The data cloud has proven to be an optimal platform for data warehousing, as demonstrated by the great success of platforms such as Snowflake and BigQuery. As companies embrace the data cloud technology, data leaders are facing increasing storage costs as more and more data is being relocated to the data cloud. Arguably it's crucial for a company to have one single source of truth for all of their organization’s data (that is one of the main selling points of the data cloud), but with more data comes more costs. In this blog post, we'll discuss a few ways to reduce or manage your data warehouse costs to help maximize ROI.
Costs of the Cloud
Cloud costs are based on a few factors that differ by provider, but namely the cost is a function of data storage, network usage and data processing. Generally, data cloud providers charge based on a per-use model, where customers only pay for resources they consume, providing a flexible model for organizations to easily scale resources up or down. However, it’s important for organizations to monitor usage levels and ensure that they are paying for only what they need–or risk over-spending.
Steps to Take to Reduce Warehouse Costs
Reduce Data Latency
You may have already considered this, but reducing data latency can be an effective way to reduce computational costs. Not all data models need to be updated on the hour, and reducing the number of scheduled runs can reduce costs.
Optimize the Data Model Upstream
Another method to reduce data warehouse costs is by optimizing the data model upstream. This includes employing join strategies to avoid Cartesian joins that can cause table sizes to explode. One such tool is creating a unique join key for tables that you expect to connect, and maintaining only one row per event in an activity table. By verifying that joins are properly mapped, unnecessary cost can be prevented.
Optimize Data Models Within the Warehouse
Optimizing the data model itself can also reduce the footprint of audience queries. Partitioning on a commonly filtered date column is an effective way to achieve this in BigQuery. Additionally, clustering on commonly filtered fields can reduce table scans, which is useful when not using date partitioning.
Set up Monitoring and Alerts
It's important to track and monitor costs to ensure that data warehousing expenses remain within budget. Many data warehouses provide query histories and the ability to query storage sizes. At Flywheel, we use tagging to label our data models, highlighting those that are significantly more costly than others. We also set up alerts for when data models exceed certain cost thresholds beyond their historical averages.
Use Incremental Models
Another optimization technique is to use incremental models. Incremental models only scan necessary records when merging data, which can reduce costs. However, how you scan when merging data can also create unnecessary costs. If your table is partitioned, filtering by the maximum or minimum partition id can reduce costs. For example, in BigQuery, you can use the following code snippet to filter by the maximum partition id:
This DBT snippet does a full table scan, which increases costs as tables get larger.
{% if is_incremental() %} WHERE response_date > (SELECT MAX(response_date) FROM {{ this }}) {% endif %}
Using this pattern below allows DBT to scan the partition metadata to find the most recent partition id, in this case a date, to only do a partial table scan. In our use cases, this has been found to decrease costs by up to 10x on the per-model basis.
{%- call statement('max_partition', fetch_result=True) -%} SELECT parse_date('%Y%m%d',max(partition_id)) FROM `{{ project }}.{{ this.schema }}.INFORMATION_SCHEMA.PARTITIONS` WHERE table_name = "{{ this.name }}" AND partition_id != "__NULL__" {%- endcall -%} {%- set max_date = load_result('max_partition')['data'][0][0] -%} SELECT * FROM {{table}} {% if is_incremental() %} WHERE batch_date >= '{{ max_date }}' {% endif %}
This code snippet scans the partition metadata to find the most recent partition id and allows DBT to do a partial table scan.
It's important to note that not all data models are the same, and different strategies may be required depending on the specific use case. Employing data model optimization and incremental models while also being mindful of join strategies and how data is scanned during merge operations can significantly reduce data warehouse costs.
Auto-Reduce Snapshotting Frequency and Storage Length
Another way to reduce costs is to auto-reduce snapshotting frequency and storage length. We only run snapshotting if the tables that feed the audience have been updated since the last run. Additionally, we delete snapshot tables when audiences are deleted to minimize unnecessary storage costs.
By employing these optimization techniques and cost-tracking strategies, data warehouse costs can be significantly reduced without sacrificing performance or functionality.
How Flywheel Helps Companies Reduce Costs and Drive Value
At Flywheel, we understand the importance of reducing data warehouse costs and preventing them from spiraling out of control. We are committed to driving the most value for our customers while ensuring that their data warehousing expenses remain within budget. While the cost savings efforts we're suggesting might seem trivial for your organization today, we’ve helped our enterprise customers with tens of millions of records reduce or maintain costs with updates to their processes and our products.
We have implemented several product updates to help our customers reduce their data warehouse costs. For instance, we won't auto-run audience calculations until you fully generate an audience. This feature ensures that unnecessary computational resources are not wasted on incomplete audience calculations.
We have also introduced the ability to set end dates on audience exports. Audiences set to export to destinations are now set to run for a specific period, after which they will be automatically stopped. This reduces unnecessary data storage and computational costs, particularly for campaigns that only run for a limited time.
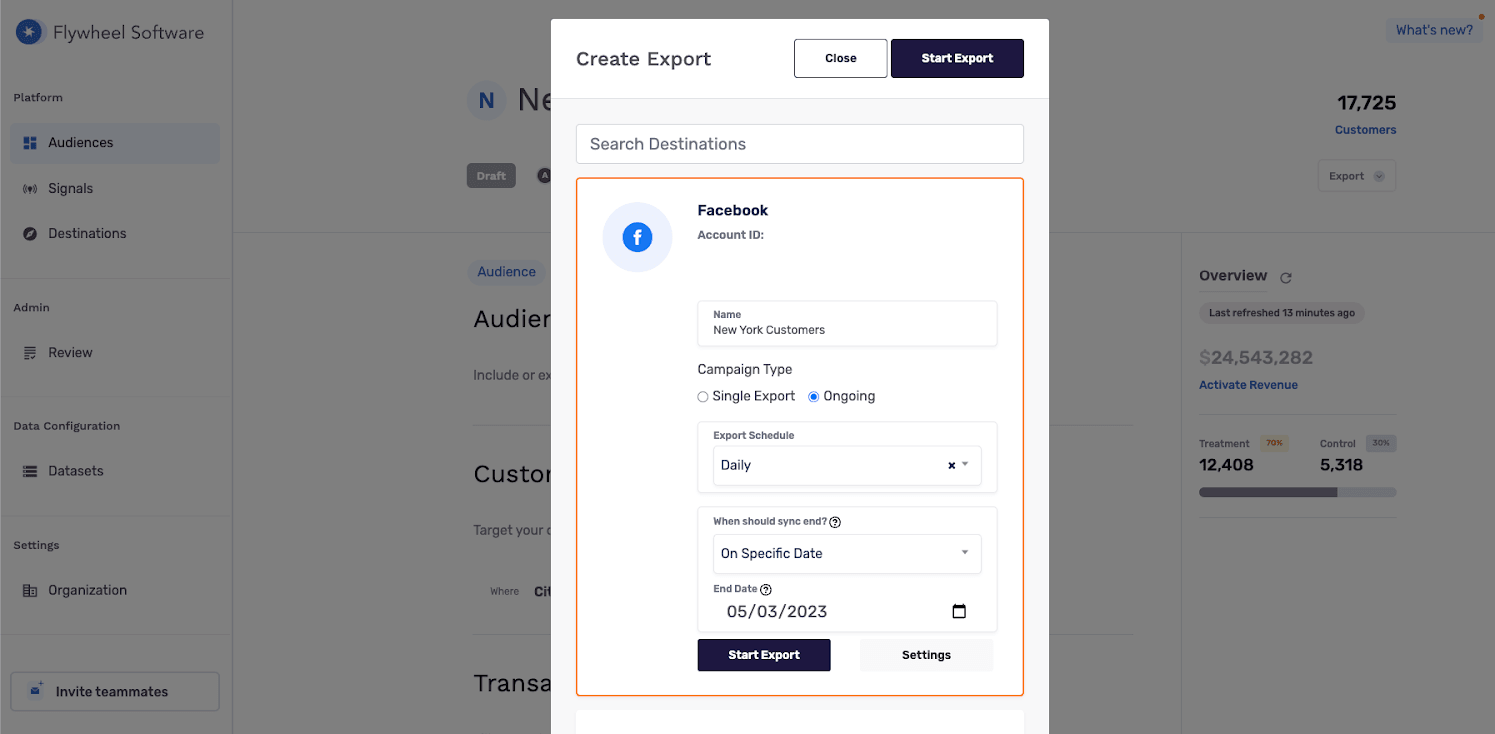
As we mentioned above, we introduced the ability to right-size snapshot storage for both historical and future snapshots. By deleting snapshots rather than increasing storage by snapshotting every time, our customers can replicate their datasets and compare old vs. new snapshots as things change over time. This process ensures that our customers only store relevant data, reducing unnecessary data storage costs.
In conclusion, Flywheel is committed to helping our customers reduce their data warehouse costs while ensuring that they get the most value from their data. Our product updates are designed to optimize computational resources and reduce unnecessary data storage costs without compromising performance or functionality.
Reach out to your Solutions Architect or contact sales to learn how Flywheel can help you to manage data warehouse costs while maximizing value.